How to get More Out of Your Meetings using Whisper and Semantic Search in Google Sheets
…or how to use your clients’ words against them.
Why semantic search?
Transcription using ML is prone to errors. Using fuzzy semantic search it is possible to overcome those errors by ranking the search results by content relevance. You could even ask it a question, and the search would respond with potential answers hidden in the transcription.
Why would you even need semantic search?
- You’ll be able to search through transcribed text and reference the exact timestamps in the original audio file
- You can leave this process in the background while eating lunch after an exhausting meeting
- You love using your clients’ words against them
- Someone sent you a really long voice message that you just don’t want to listen to
- Because it’s cool
- It’s very easy to try and all the technology you need is provided by Google
What do you need to follow along?
- Google account
- Google Sheets with Semantic Reactor add-on installed
- This cool Google Colaboratory Notebook
- Audio recording of your choice (ideally of a long meeting you need to analyze) in mp3 format
- I recommend this online tool for audio format conversion if necessary
Motivation
If you’re anything like me, you consider time a very precious commodity. Especially when you have to efficiently come up with a plan during a meeting with your stakeholders. Every minute counts and every word must be carefully chosen. During, sometimes intense discussions, my memory can become fuzzy, causing me to forget the exact words used and leaving me with only a few key points once the dust has settled. As time continues after the meeting is over, each passing minute becomes another memory of the conversation gradually fading away. I have always longed for a more optimized solution to recall and analyze the conversation (Any other overthinkers? Just me? Okay…).
I tried rewatching recordings…
…and that didn’t go all too well. A considerable portion of my pursuit of a master’s degree occurred amid the pandemic during which it became a common practice to record lectures. Although that period provided me with more free time, I found myself preferring to read the material at my own pace, resulting in the recordings going unreviewed even though I had the best intentions of revisiting them.
Watching recordings simply took too long to extract meaningful insights from.
Rewatching was a waste of precious time for me.
I needed something better.
This is where OpenAI’s Whisper comes to rescue — sort of.
OpenAI developed Whisper, an advanced speech recognition deep learning model that uses a large, diverse multilingual dataset to transcribe and translate speech between multiple languages. The best part about it is that OpenAI decided to make it open-source, which means it is completely free to use for research — or other purposes.
Using Whisper you can generate a list of sentences from audio like in the example photo below.
![]()
Extracted speech with timestamps imported into Google Sheets
When it comes to transcribing audio files, Whisper is among the most advanced automatic speech recognition models out there. But even with all that power, sometimes it’s not enough to catch everything. As the saying goes, “whispering sweet nothings” may be great for romance, but it’s not so great for accurate transcription. Whisper may be able to pick up on many different accents, even in the presence of background noise, but it still has its limitations. It’s not always possible to catch every word or phrase, especially if the audio quality is poor or if people are speaking quickly or indistinctly.
It’s important to keep in mind that humans are prone to making mistakes during conversations, especially when dealing with multiple languages and accents. In our case, where both us and our stakeholders are not native English speakers, this increases the likelihood of errors.
As a result, relying solely on regular search did not yield the results I needed, as the terms I was looking for would sometimes have been misunderstood or just missed completely.
Yet again — I needed something even better.
But first, let me show you how to extract your own transcriptions.
Extracting speech from audio file
Please refer to Google Colaboratory Notebook I shared at the top.
By following a few simple steps, you will be creating transcriptions in no time. After looking at the provided photo of the notebook, you will need to follow the instructions outlined by red numbers in order:
- Open the Files tab by clicking on the orange file on the left side and dropping your desired audio file into sample_data folder.
- You will be able to see your file uploading at the bottom of the Files tab.
- While the file is uploading change the variable audio_file_name into the exact name of your file. Variable transcription_name will be the name of the file containing your transcription with timestamps. Make sure to leave .tsv at the end of the file name.
- You’re ready to go. Press Runtime -> Run All and wait for your file to download automatically.
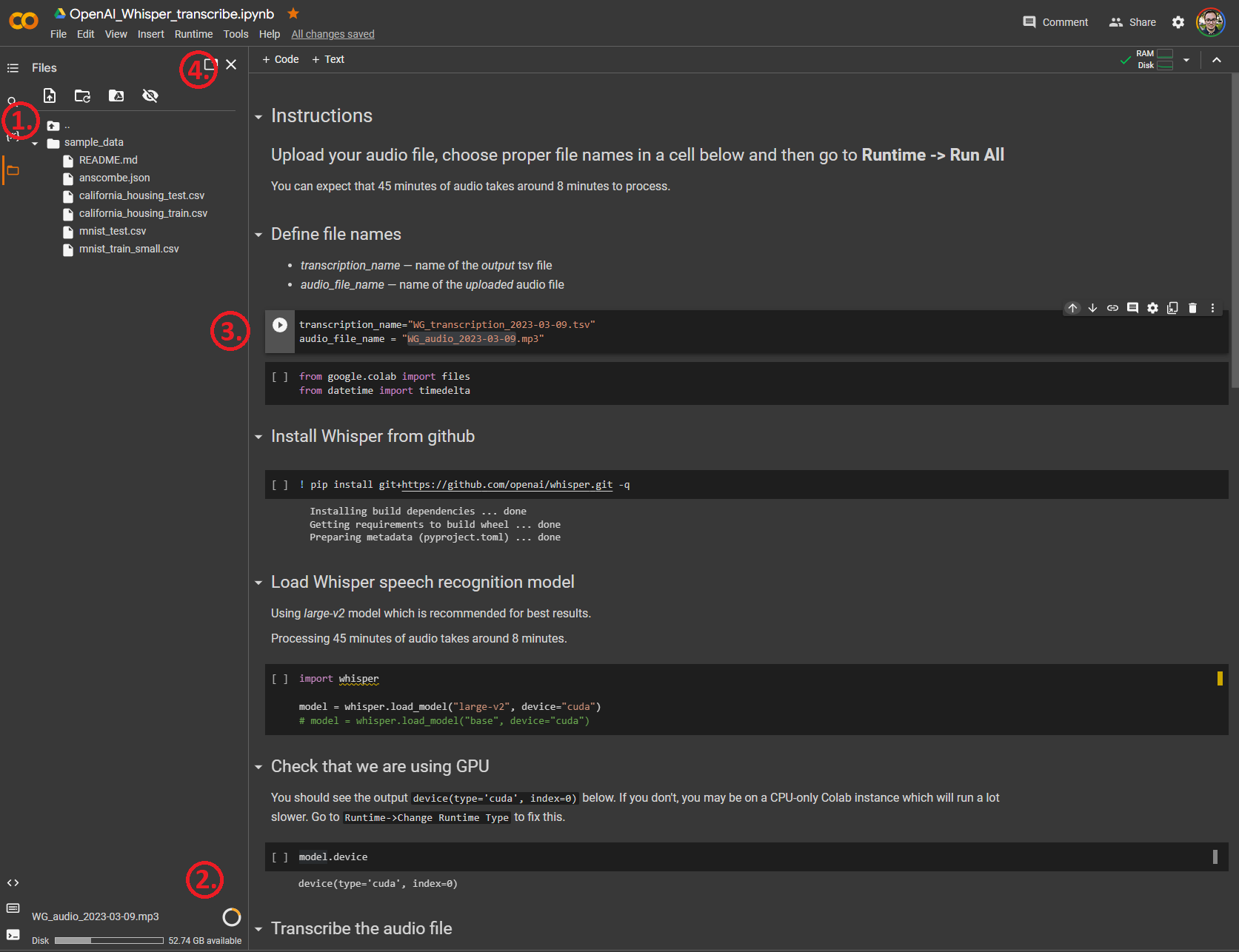
Google Colaboratory Notebook containing code for transcription using Whisper
At this point you can snooze while you wait for your transcription. Or, you know, keep reading the article.
After the notebook runs through all the cells and the .tsv file downloads, you can import it into Google Sheets by clicking on File → Import → Upload, uploading the file and clicking on Open now after it finishes importing.
The power of semantic search
In Google Sheets, no less. Completely free and ready to use with pretrained models.
In order to start using semantic search, after you installed Semantic Reactor, you can simply click on Extensions → Semantic Reactor → Start and the add-on will open on the right side of the sheet.
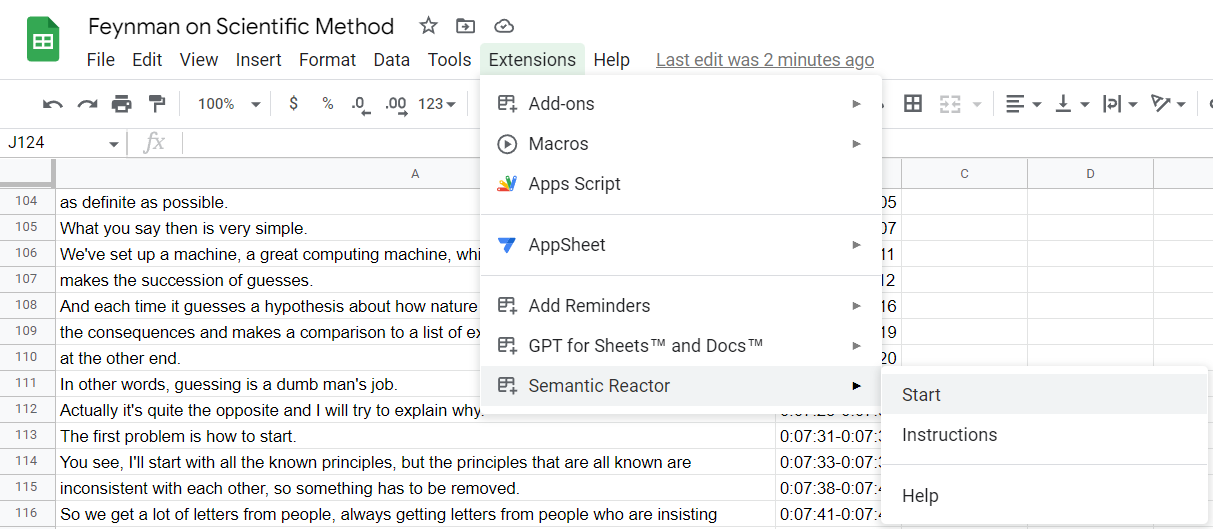
Starting Semantic Reactor in Google Sheets
Feel free to play around with different models and rank methods to see what works best for you.
In my experience, I’ve found it enjoyable and very amusing to utilize the Input/Response method to search by asking a specific questions and receiving relevant answers in response. On the other hand, if your goal is to find the best matching sentences and words, I recommend using Semantic Similarity method.
A few photos showcasing cherry picked results from a transcribed Feynman’s lecture on Scientific Method are included below.
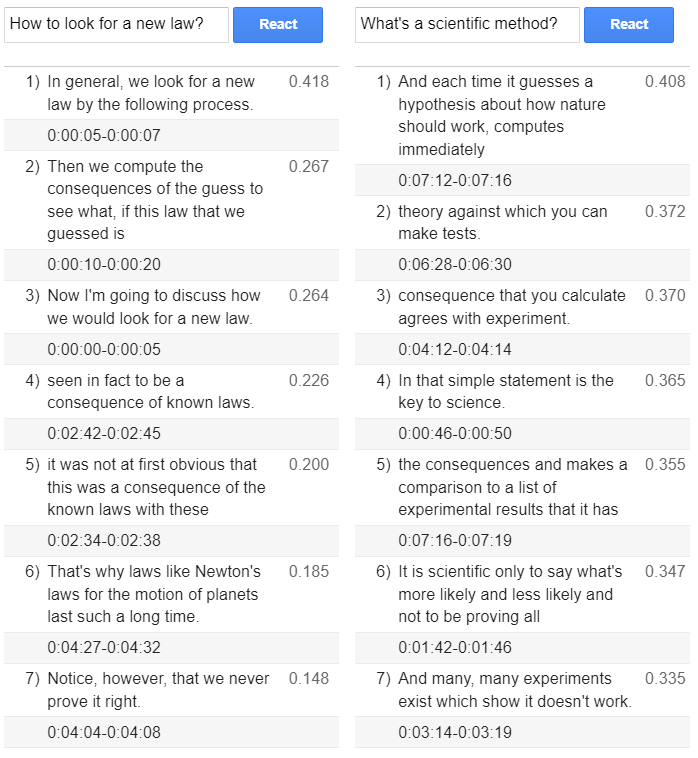
Semantic search using Input/Response method
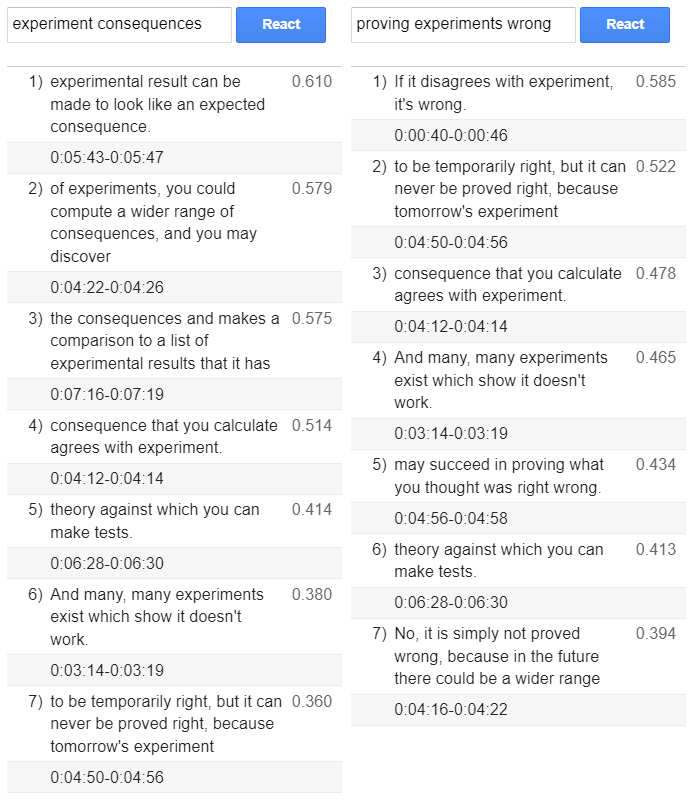
Semantic search using Semantic Similarity method
In conclusion
When it comes to transcribing conversations, traditional methods can be time-consuming, and relying on machine learning transcription tools alone can lead to errors. That’s where the power of semantic search comes in. Whisper and other similar models will inevitably make mistakes, but you can overcome most of these errors by using fuzzy semantic search. Semantic search is a technique that uses deep learning models to understand the meaning behind words and phrases in order to provide search results with relevant context. When applied to conversation transcripts, semantic search makes it easier to find specific information quickly even when text is full of typos and errors.
In the future, if your stakeholders claim that they cannot recall what they shared with you in the previous meeting, you can confidently assert that you do, and even provide them with a fast recollection. Within a margin of error, of course.

